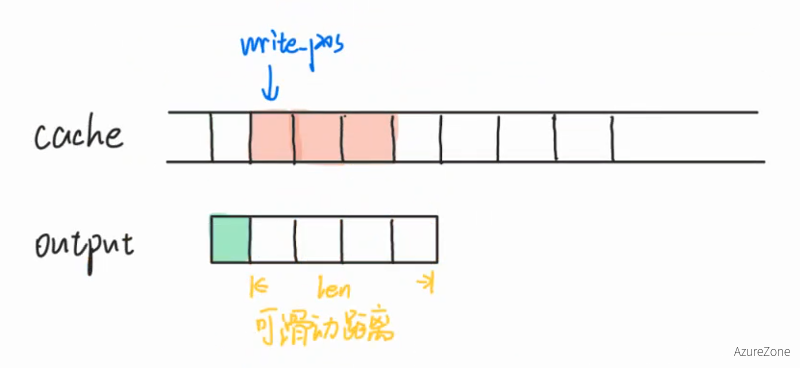
//! \details This function accepts a substring (aka a segment) of bytes, //! possibly out-of-order, from the logical stream, and assembles any newly //! contiguous substrings and writes them into the output stream in order. voidStreamReassembler::push_substring(const string &data, constsize_t index, constbool eof){ // extend_size: 按照index和data.length()扩容后的大小,只会按扩大的来扩容 size_t extend_size = index + data.length();
// 记录EOF的位置 if (eof) { end_p = extend_size; }
// 扩容只会变大,不会缩小 if (extend_size > cache.length()) { cache.resize(extend_size); dirty_check.resize(extend_size); }
Test Failure on expectation: Expectation: stream_out().buffer_size() returned 0, and stream_out().read(0) returned the string ""
Failure message: The reassembler was expected to have `0` bytes available, but there were `4`
List of steps that executed successfully: Initialized (capacity = 6) Action: substring submitted with data "defg", index `3`, eof `0` Expectation: net bytes assembled = 0 Action: substring submitted with data "abc", index `0`, eof `0` Expectation: stream_out().buffer_size() returned 6, and stream_out().read(6) returned the string "abcdef" Expectation: net bytes assembled = 6 Action: substring submitted with data "kmg", index `7`, eof `0`
Exception: The reassembler was expected to have `0` bytes available, but there were `4`
Test Failure on expectation: Expectation: not at EOF
Failure message: The reassembler was expected to **not** be at EOF, but was
List of steps that executed successfully: Initialized (capacity = 6) Action: substring submitted with data "defx", index `3`, eof `1` Expectation: net bytes assembled = 0 Action: substring submitted with data "abc", index `0`, eof `0` Expectation: stream_out().buffer_size() returned 6, and stream_out().read(6) returned the string "abcdef" Expectation: net bytes assembled = 6 Action: substring submitted with data "g", index `6`, eof `0` Expectation: stream_out().buffer_size() returned 1, and stream_out().read(1) returned the string "g"
Exception: The reassembler was expected to **not** be at EOF, but was